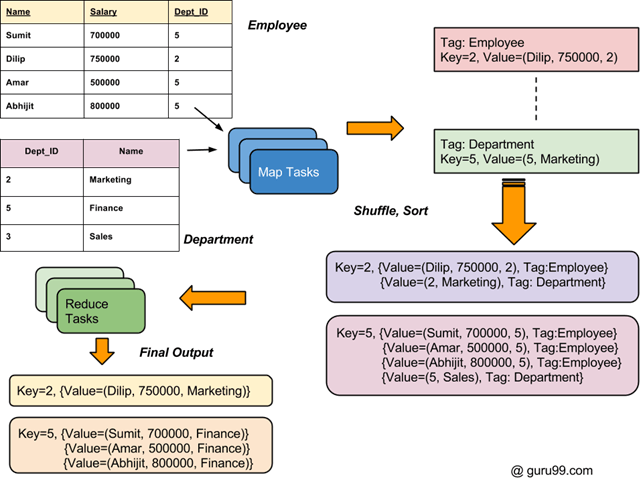
![]() It’s been awhile since I last posted, and like last time I took a big break, I was taking some classes on Coursera. This time it was Functional Programming Principals in Scala and Principles of Reactive Programming. I found both of them to be great courses and would recommend taking either one if you have the time. In this post we resume our series on implementing the algorithms found in Data-Intensive Text Processing with MapReduce, this time covering map-side joins. As we can guess from the name, map-side joins join data exclusively during the mapping phase and completely skip the reducing phase. In the last post on data joins we covered reduce side joins. Reduce-side joins are easy to implement, but have the drawback that all data is sent across the network to the reducers. Map-side joins offer substantial gains in performance since we are avoiding the cost of sending data across the network. However, unlike reduce-side joins, map-side joins require very specific criteria be met. Today we will discuss the requirements for map-side joins and how we can implement them.
It’s been awhile since I last posted, and like last time I took a big break, I was taking some classes on Coursera. This time it was Functional Programming Principals in Scala and Principles of Reactive Programming. I found both of them to be great courses and would recommend taking either one if you have the time. In this post we resume our series on implementing the algorithms found in Data-Intensive Text Processing with MapReduce, this time covering map-side joins. As we can guess from the name, map-side joins join data exclusively during the mapping phase and completely skip the reducing phase. In the last post on data joins we covered reduce side joins. Reduce-side joins are easy to implement, but have the drawback that all data is sent across the network to the reducers. Map-side joins offer substantial gains in performance since we are avoiding the cost of sending data across the network. However, unlike reduce-side joins, map-side joins require very specific criteria be met. Today we will discuss the requirements for map-side joins and how we can implement them.
Map-Side Join Conditions
To take advantage of map-side joins our data must meet one of following criteria:
